2026年6月!北大联合研究揭示AI生成人体动作难题
一个隐藏了十年的编码陷阱
你可曾思索过, 在AI生成一个奔跑动作之际, 它全然不知晓你的脚究竟何时落地? 这并非是技术方面存在的缺陷, 而是由编码方式所埋下的系统性盲点。在2026年最新的研究中发现, 传统的单流编码将关节姿态以及运动速度混合在一起进行处理, 致使模型始终都学不会物理细节——所生成的动作在前半部分尚可, 后半部分就开始出现身体漂移、关节错位的情况, 仿佛是在冰面上跳舞那般失控。
频率分析:发现不对称的起点
为什么5个成分就能覆盖93%的姿态信息
研究团队针对每帧动作数据的各个维度, 开展了细致入微的频谱分析, 运用“低频比例”这一指标, 对信号平滑度予以量化。其结果, 着实令人大为震惊: 用于描述关节位置的信号, 呈现出极为“低频”之态, 恰似一首曲子当中的舒缓旋律那般, 仅仅借助5个低频成分, 便能够涵盖整个信号93%的能量。这所蕴含的意义在于, 姿态信息呈现出高度集中之状况, 具备巨大的压缩空间。
速度信号却需要25个成分才能覆盖80%
然而, 用于描述关节移动速度的信号, 其呈现出的状态是完全相反的, 该信号所具备的能量, 分散于更为宽广的频率范围之中。若要达成覆盖80%的物理流能量这一目标, 起码需要25个频率成分, 此数量是姿态信号所需频率成分数量的5倍。实际上, 这两种信号在本质层面, 属于两套不同的语言信息, 当前运用同一本字典去进行翻译, 最终必然会偏向更具“主流”性质的姿态一方。
双流编码:把两套语言分开翻译
基础流保留5个低频成分,物理流保留25个
DSFT方案的核心要点在于, 不再将各方面进行混淆处理, 基础流仅仅留存下最先的5个低频成分, 并专门用以保存姿态结构, 物理流则保留前25个成分, 从而完整地覆盖速度的高频细节, 在压缩结束之后, 它们各自经由独立的BPE编码器, 进而生成基础词元和物理词元这两套序列。
双流方案的rFID从0.9461骤降至0.1868
更为重要的是效果方面的对比,一项衡量着生成动作分布跟真实动作分布之间差异的rFID指标显现在此时, 单流方案所对应的该指标数值为0.9461, 与之形成鲜明对比的是, 双流方案的此项数值径直下降到了0.1868, 实现了5倍的提升幅度。单流编码的情况是, 因高频信息出现丢失现象, 致使生成的动作分布已然严重地偏离了真实数据, 然而双流独立编码却完整地保留住了两类信号各自的统计特性, 出现这样的对比结果。
两步生成:先定姿态再补物理细节
注意力机制让物理流回头看姿态词元
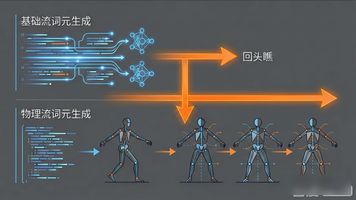
倘若物理信号是依存姿态基础, 脚部如何移动, 取决于腿部所处哪种姿态, 那么生成顺序必然得进行分层。模型先是生成基础流词元, 之后再去生成物理流词元。当物理流进行生成时, 能借着注意力机制“回头瞧”所有已然生成的姿态词元, 从而做出更为准确的物理预测。
扩展Qwen3.5词汇表新增8195个运动专用词元
研究群体将原本Qwen3.5的二四八万三千二百个词汇扩充至二十五万六千五百一十五个, 新增有四千零九十六个基础流词元、四千零九十六个物理流词元, 再加上开始、分隔、结束这三个结构标记。每一个动作样本被表征成一个统一序列: 开始标记到基础流词元到分隔标记到物理流词元到结束标记。
两阶段训练:冻结大模型只练新技能
第一阶段500步让模型认识新词元
训练不是一下子就能完成的, 第一阶段称作“词元嵌入预热”, 需冻结Qwen3.5所有层的参数, 仅训练新增的8,195个词元嵌入, 运用优化器跑500步, 以此让模型明白这些新词元大致处于怎样的语义空间, 这如同先教导一个人认识新汉字, 接着教他利用这些字撰写文章。
第二阶段用LoRA适配同时保持原始权重冻结
依据23384条带有文字描述的动作数据, 在第二阶段开展纯文本驱动式训练。全过程里, Qwen3.5的原始权重一直维持冻结状态, 既存留着预训练语言模型的通用解读能力, 又借助LoRA适配促使其学会运动从而生成全新技能。另外存在一个生成方面的约束点, 用以防止两种流词元相互混杂在一起, 保证基础姿态先于物理细节出现。
性能实测:多样性得分9.548逼近真实数据9.503
场景图像辅助下对比方法全面落败
在标准测试集当中, DSFT于多样性指标方面, 获取到了把真实数据分布最靠近的得分9.548, 其中真实数据的值是9.503;在多模态性这一方面, 达到了2.821, 此为所有生成方法里最高的。需要特别提及的是, DSFT还另外运用了场景图像当作输入条件, 然而对比方法均仅仅使用文字描述——在条件更为丰富的情形下效果更佳, 表明场景视觉信息的确能够助力生成更契合实际情境的动作。
真实机器人跑起来验证动作生成无误
测试了三个示例的研究团队, 是在真实机器人之上进行的测试, 且全部成功完成了文字所描述的动作。那这就意味着, 整套技术链路, 不但在数据方面呈现出良好的状态, 而且在实际硬件方面也是能够顺畅运行的。有着更少的脚滑现象, 有着更丰富多样的动作变化, 有着更契合场景的整体表现, 这些皆是双流编码所带来的直接益处。
现如今, 我满心好奇, 你认为在AI生成动作期间, 最令你记忆深刻的“翻车”情景是啥, 是行走之际脚模进地面, 还是跑步之时身体陡然旋转一百八十度, 欢迎于评论区域分享你所目睹的AI动作翻车的著名场景, 点赞并收藏此文本, 下次碰见朋友探讨AI时, 你便能告知他们真正的魔鬼并非存在于算法当中, 而是在字典里面?
询问: 于你所见识过的, 由AI产出的动作之中, 最为离奇的物理错误是怎样的情况呢? 敬请在评论区域进行吐槽!




最新评论